Guardrails are safety and compliance rules that evaluate every user message before the AI assistant responds. Each guardrail contains a natural-language rule that an LLM evaluates independently — if any guardrail fails, the response is blocked. Use guardrails to enforce content safety, privacy protection, regulatory compliance, and custom business policies.
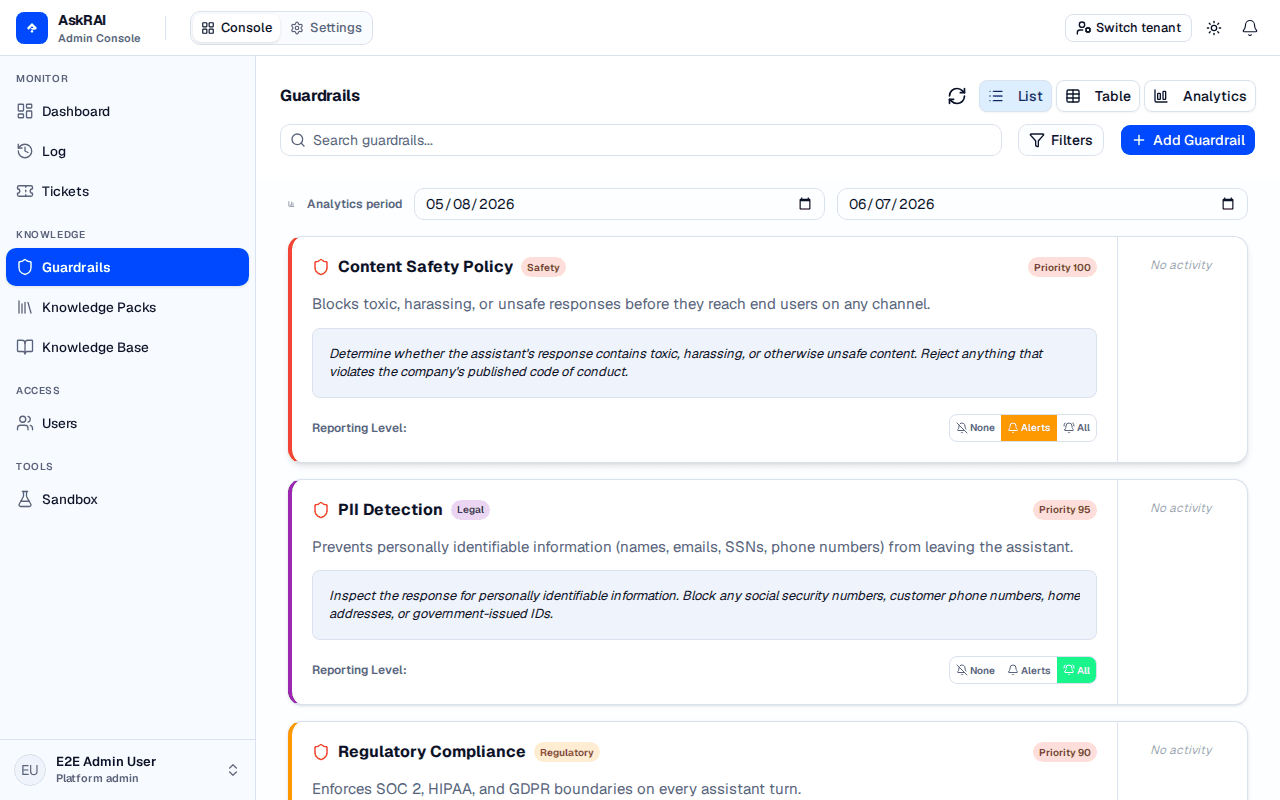
The Guardrails page displays all configured guardrails with their category, priority, and reporting level.
Key Concepts
Before configuring guardrails, understand how they work at runtime:
- Independent evaluation — each guardrail is evaluated by a separate LLM call, so rules do not interfere with one another.
- Tripwire blocking — if any single guardrail fails (the user message violates the rule), the entire response is blocked.
- Concurrent execution — guardrails run in parallel (up to three at a time) to minimize latency.
- Audit recording — every evaluation result (pass or fail) is recorded in the conversation audit trail for analytics.
Viewing Guardrails
The Guardrails page offers three view modes, switchable from the toolbar:
- List view (default) — card-based layout showing each guardrail with its name, category badge, priority score, and fire rate badge.
- Table view — sortable columns for name, description, category, priority, reporting level, fire count, fire rate, and a sparkline trend.
- Analytics view — dashboard with compliance trend charts, category distribution, top-fired guardrails, and false-positive rates.
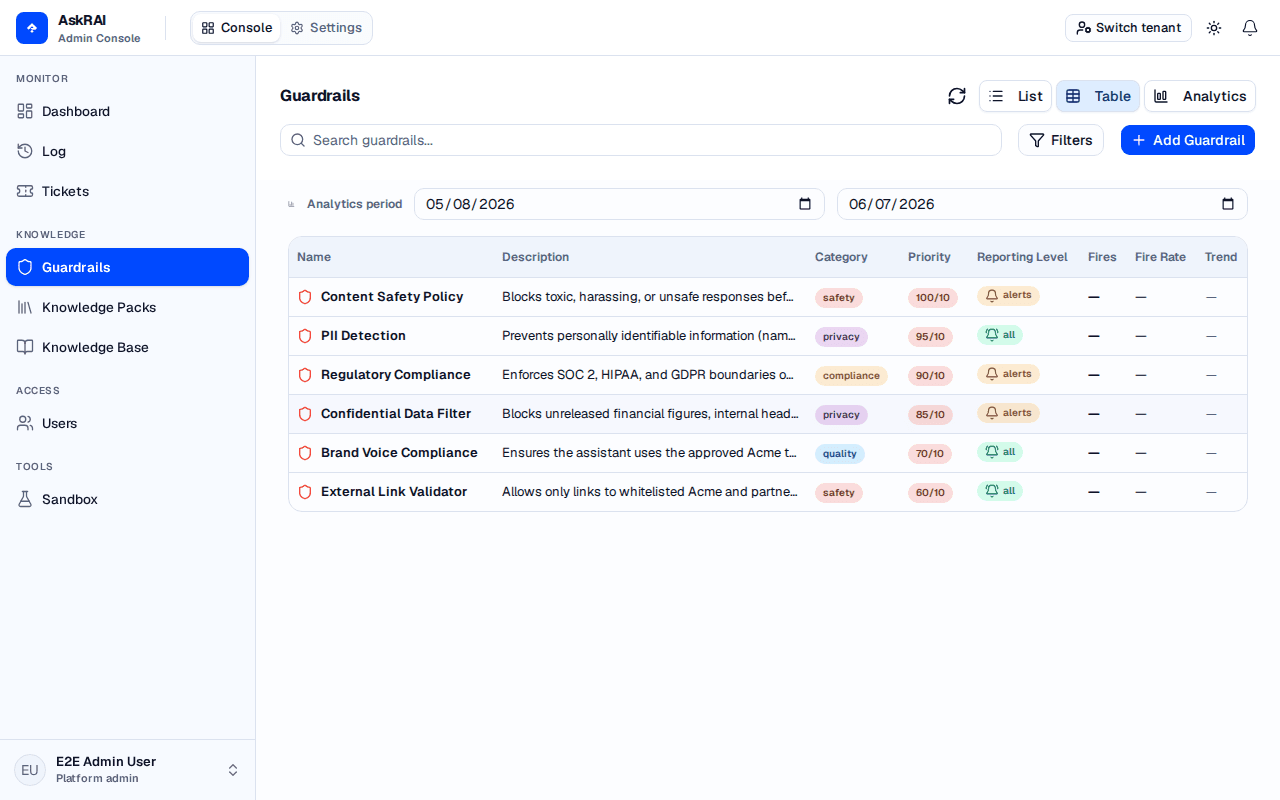
Table view lets you sort guardrails by name, category, or priority and see fire metrics at a glance.
You can filter guardrails using the toolbar:
- Search — full-text search across name, description, and prompt fields (debounced 500 ms).
- Category filter — narrow to a specific category (Safety, Compliance, Quality, Privacy, or Custom).
- Priority filter — filter by priority range: High (8–10), Medium (5–7), or Low (0–4).
- Reporting level filter — filter by None, Alerts, or All.
Active filters appear as removable chips below the toolbar. Click Clear All to reset.
Creating a Guardrail
Open the Create Dialog
Click Add Guardrail in the top-right corner of the Guardrails page.
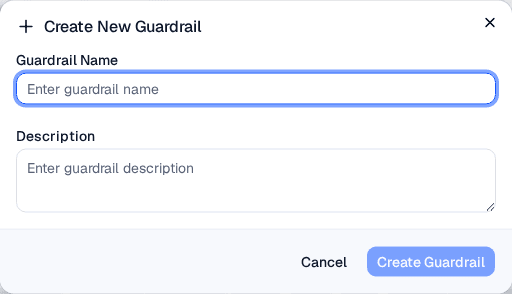
The create dialog asks for a name and optional description.
Enter a Name and Description
Type a descriptive name for your guardrail (required) and an optional description explaining its purpose.
Configure the Guardrail
After clicking Create Guardrail, the edit modal opens automatically. Fill in the remaining fields:
- Category — select the type of rule (Safety, Compliance, Quality, Privacy, or Custom).
- Priority — set a priority score from 0 to 10. Higher values indicate more critical rules.
- Reporting Level — choose what to log: None (evaluate silently), Alerts (log violations only), or All (log every evaluation).
- Prompt — write the natural-language rule the LLM uses to evaluate user messages. Be specific about what should be allowed and what should be blocked.
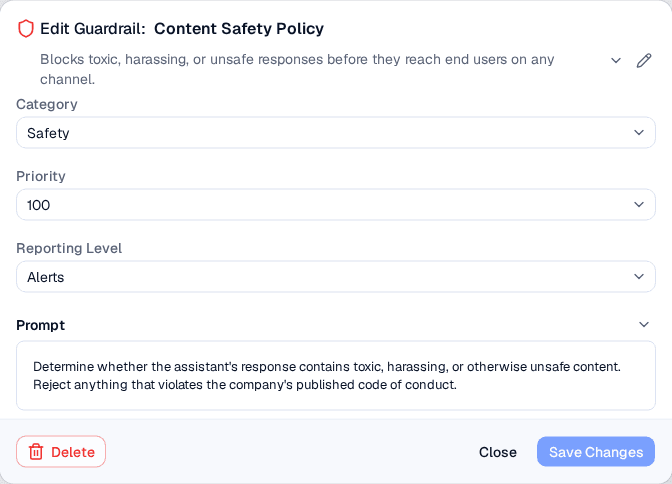
The edit modal provides access to all guardrail configuration fields including the evaluation prompt.
Save Changes
Click Save Changes to persist your guardrail. A success message appears briefly, and the guardrail is immediately active for new conversations.
Write guardrail prompts in clear, specific language. For example, instead of "block bad content," write "set is_adhere_to_rules to false if the message contains personally identifiable information such as social security numbers, credit card numbers, or home addresses."
Editing a Guardrail
Click any guardrail card (or table row) to open the edit modal. You can modify any field — name, description, category, priority, reporting level, and prompt. Click Save Changes when finished.
Changes to guardrails take effect on the next conversation. Active conversations continue using the guardrail configuration that was loaded when they started.
Deleting a Guardrail
Open the guardrail you want to remove, then click Delete at the bottom-left of the edit modal. Confirm the deletion in the dialog that appears. Deleted guardrails are permanently removed and cannot be recovered.
Field Reference
| Field | Description | Required | Values |
|---|---|---|---|
| Name | Display name shown in the guardrails list | Yes | Free text |
| Description | Narrative explanation of the guardrail's purpose | No | Free text |
| Category | Classification of the guardrail type | Yes | Safety, Compliance, Quality, Privacy, Custom |
| Priority | Criticality score for admin triage (does not affect evaluation order) | Yes | 0–10 (integer) |
| Reporting Level | Controls what gets logged to the audit trail | Yes | None, Alerts, All |
| Prompt | Natural-language instruction the LLM uses to evaluate user messages | Yes | Free text |
Analytics
Switch to the Analytics view to see guardrail performance metrics over a configurable date range:
- Compliance trend — daily line chart showing the percentage of conversations that passed all guardrails.
- Category distribution — breakdown of guardrail fires by category.
- Top fired guardrails — ranking of guardrails by fire count.
- False positive rates — per-guardrail ratio of fires that were later marked as false positives.
In list and table views, each guardrail also shows a fire badge with the total fire count and fire rate for the selected date range. The badge color indicates severity: green (below 15%), orange (15–50%), and red (above 50%).
Related Pages
- Knowledge Packs — manage the content collections your assistant draws from
- Knowledge Base — create and edit the Q&A pairs that power responses
- Conversation Logs — review conversation history and guardrail evaluation results
- Settings — configure confidence thresholds and escalation rules